In 1990, John Quarterman, a networking consultant and UNIX expert, published a comprehensive survey of the state of computer networks. In a brief section on the potential future for computing, he predicted the appearance of a single global network for “electronic mail, conferencing, file transfer, and remote login, just as there is now one worldwide telephone network and one worldwide postal system.” But he did not assign any special significance to the Internet in this process. Instead, he assumed that the worldwide net would “almost certainly be run by government PTTs”, except in the United States, “where it will be run by the regional Bell Operating Companies and the long-distance carriers.”
It will be the purpose of this post to explain how, in a sudden eruption of exponential growth, the Internet so rudely upset these perfectly natural assumptions.
Passing the Torch
The first crucial event in the creation of the modern Internet came in the early 1980s, when the Defense Communication Agency (DCA) decided to split ARPANET in two. The DCA had taken control of the network in 1975. By that time, it was clear that it made little sense for the ARPA Information Processing Techniques Office (IPTO), a blue sky research organization, to be involved in running a network that was being used for participants’ daily communications, not for research about communication. ARPA tried and failed to hand off the network to private control by AT&T. The DCA, responsible for the military’s communication systems, seemed the next best choice.
For the first several years of this new arrangement, ARPANET prospered under a regime of benign neglect. However, by the early 1980s, the Department of Defense’s aging data communications infrastructure desperately needed an upgrade. The intended replacement, AUTODIN II, which DCA had contracted with Western Union to construct, was foundering. So DCA’s leaders appointed Colonel Heidi Hieden to come up with an alternative. He proposed to use the packet-switching technology that DCA already had in hand, in the form of ARPANET, as the basis for the new defense data network.
But there was an obvious problem with sending military data over ARPANET – it was rife with long-haired academics, including some who were actively hostile to any kind of computer security or secrecy, such as Richard Stallman and his fellow hackers at the MIT Artificial Intelligence Lab. Heiden’s solution was to bifurcate the network. He would leave the academic researchers funded by ARPA on ARPANET, while splitting the computers used at national defense sites off onto a newly formed network called MILNET. This act of mitosis had two important consequences. First, by decoupling the militarized and non-militarized parts of the network, it was the initial step toward transferring the Internet to civilian, and eventually, private, control. Secondly, it provided the proving ground for the seminal technology of the Internet, the TCP/IP protocol, which had first been conceived half a decade before. DCA required all the ARPANET nodes to switch over to TCP/IP from the legacy protocol by the start of 1983. Few networks used TCP/IP at that point in time, but now it would link the two networks of the proto-Internet, allowing message traffic to flow between research sites and defense sites when necessary. To further ensure the long-term viability of TCP/IP for military data networks, Heiden also established a $20 million fund to pay computer manufacturers to write TCP/IP software for their systems (1).
This first step in the gradual transfer of the Internet from the military to private control provides as good an opportunity as any to bid farewell to ARPA and the IPTO. Its funding and influence, under the leadership of J.C.R. Licklider, Ivan Sutherland, and Robert Taylor, had produced, directly or indirectly, almost all of the early developments in interactive computing and networking. The establishment of the TCP/IP standard in the mid-1970s, however, proved to be the last time it played a central role in the history of computing (2).
The Vietnam War provided the decisive catalyst for this loss of influence. Most research scientists had embraced the Cold war defense-sponsored research regime as part of a righteous cause to defend democracy. But many who came of age in the 1950s and 1960s lost faith in the military and its aims due to the quagmire in Vietnam. That included Taylor himself, who quit IPTO in 1969, taking his ideas and his connections to Xerox PARC. Likewise, the Democrat-controlled Congress, concerned about the corrupting influence of military money on basic scientific research, passed amendments requiring defense money to be directed to military applications. ARPA reflected this change in funding culture in 1972 by renaming itself as DARPA, the Defense Advanced Research Projects Agency.
And so the torch passed to the civilian National Science Foundation (NSF). By 1980, with $20 million dollars in funding, the NSF accounted for about half of federal computer science research spending in the U.S, about $20 million (3). Much of that funding would soon be directed toward a new national computing network, the NSFNET.
NSFNET
In the early 1980s, Larry Smarr, a physicist at the University of Illinois, visited the Max Planck Institute in Munich, which hosted a Cray supercomputer that it made readily available to European researchers. Frustrated at the lack of equivalent resources for scientists in the U.S., he proposed that the NSF fund a series of supercomputing centers across the country (4). The organization responded to Smarr and other researchers with similar complaints by creating the Office of Advanced Scientific Computing in 1984, which went on to fund a total of five such centers, with a total five-year budget of $42 million. They stretched from Cornell in the northeast of the country to San Diego in the southwest. In between, Smarr’s own university (Illinois) received its own center, the National Center for Supercomputing Applications (NCSA).
But these centers alone would only do so much to improve access to computer power in the U.S. Using the computers would still be difficult for users not local to any of the five sites, likely requiring a semester or summer fellowship to fund a long-term visit. And so NSF decided to also build a computer network. History was repeating itself – making it possible to share powerful computing resources with the research community was exactly what Taylor had in mind when he pushed for the creation of ARPANET back in the late 1960s. The NSF would provide a backbone that would span the continent by linking the core supercomputer sites, then regional nets would connect to those sites to bring access to other universities and academic labs. Here NSF could take advantage of the support for the Internet protocols that Heiden had seeded, by delegating the responsibility of creating those regional networks to local academic communities.
Initially, the NSF delegated the setup and operation of the network to the NCSA at the University of Illinois, the source of the original proposal for a national supercomputer program. The NCSA, in turn, leased the same type of 56 kilobit-per-second lines that ARPANET had used since 1969, and began operating the network in 1986. But traffic quickly flooded those connections (5). Again mirroring the history of ARPANET, it quickly became obvious that the primary function of the net would be communications among those with network access, not the sharing of computer hardware among scientists. One can certainly excuse the founders of ARPNET for not knowing that this would happen, but how could the same pattern repeat itself almost two decades later? One possibility is that it’s much easier to justify a seven-figure grant to support the use of eight figures worth of computing power, than to justify dedicating the same sums to the apparently frivolous purpose of letting people send email to one another. This is not to say that there was willful deception on the part of the NSF, but that just as the anthropic principle posits that the physical constants of the universe are what they are because otherwise we couldn’t exist to observe them, so no publicly-funded computer network could have existed for me to write about without a somewhat spurious justification.
Now convinced that the network itself was at least as valuable as the supercomputers that had justified its existence, NSF called on outside help to upgrade the backbone with 1.5 megabit-per-second T1 lines (6). Merit Network, Inc., won the contract, in conjunction with MCI and IBM, securing $58 million in NSF funding over an initial five year grant to build and operate the network. MCI provided the communications infrastructure, IBM the computing hardware and software for the routers. Merit, a non-profit that ran a computer network that linked the University of Michigan campuses (7), brought experience operating an academic computer network, and gave the whole partnership a collegiate veneer that made it more palatable to NSF and the academics who used NSFNET. Nonetheless, the transfer of operations from NCSA to Merit was a clear first step towards privatization.
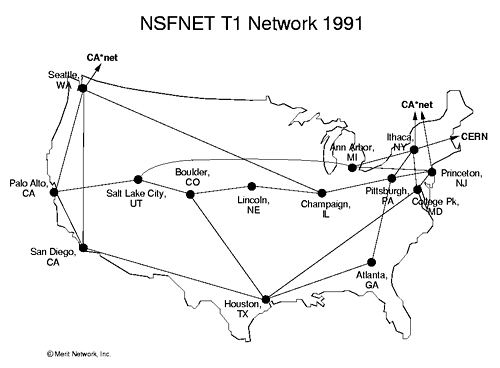
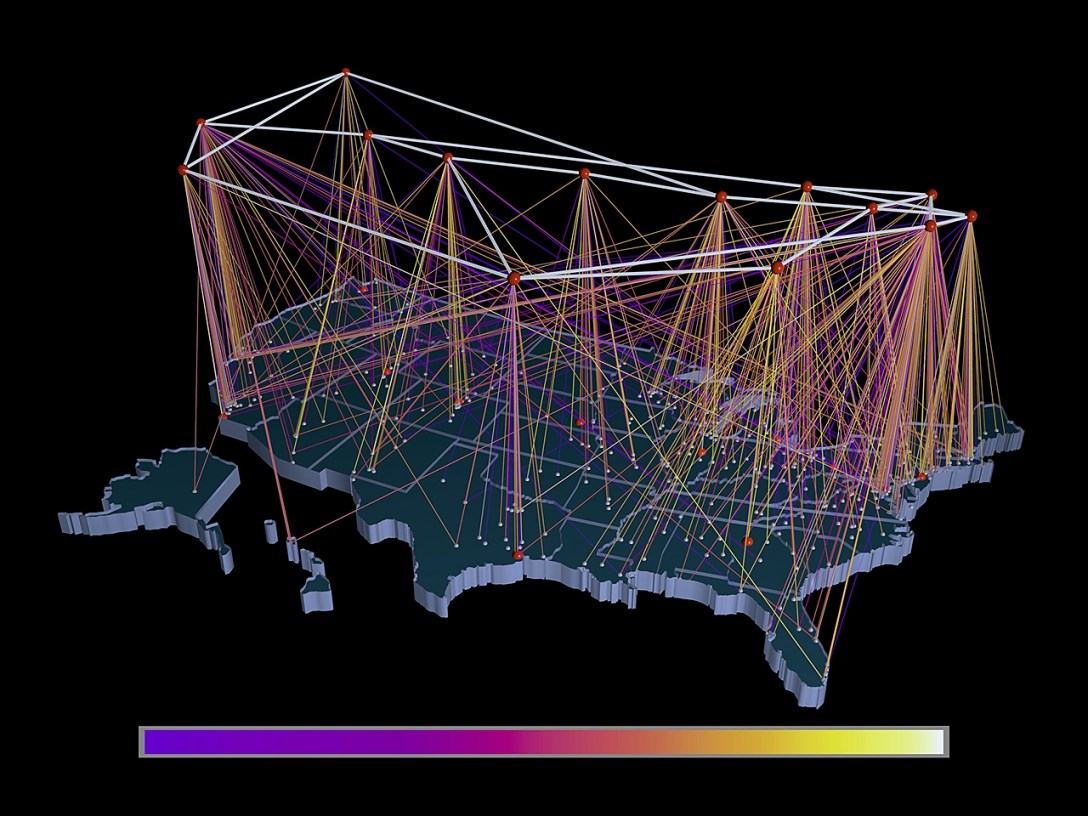
Traffic flowed through Merit’s backbone from almost a dozen regional networks, from the New York State Education and Research Network (NYSERNet), interconnected at Cornell in Ithaca, to the California Education and Research Federation Network (CERFNet -no relation to Vint), which interconnected at San Diego. Each of these regional networks also internetted with countless local campus networks, as Unix machines appeared by the hundreds in college labs and faculty offices. This federated network of networks became the seed crystal of the modern Internet. ARPANET had connected only well-funded computer researchers at elite academic sites, but by 1990 almost anyone in post-secondary education in the U.S – faculty or student – could get online. There, via packets bouncing from node to node – across their local Ethernet, up into the regional net, then leaping vast distances at light speed via the NSFNET backbone – they could exchange email or pontificate on Usenet with their counterparts across the country.
With far more academic sites now reachable via NSFNET than ARPANET, The DCA decommissioned that now-outmoded network in 1990, fully removing the Department of Defense from involvement in civilian networking.
Takeoff
Throughout this entire period, the number of computers on NSFNET and its affiliated networks – which we may now call the Internet (8) – was roughly doubling each year. 28,000 in December 1987, 56,000 in October 1988, 159,000 in October 1989, and so on. It would continue to do so well into the mid-1990s, at which point the rate slowed only slightly (9). The number of networks on the Internet grew at a similar rate – from 170 in July of 1988 to 3500 in the fall of 1991. The academic community being an international one, many of those networks were overseas, starting with connections to France and Canada in 1988. By 1995, the Internet was accessible from nearly 100 countries, from Algeria to Vietnam (10). Though it’s much easier to count the number of machines and networks than the number of actual users, reasonable estimates put that latter figure at 10-20 million by end of 1994 (11). Any historical explanation for this tremendous growth is challenging to defend in the absence of detailed data about who was using the Internet for what, at what time. A handful of anecdotes can hardly suffice to account for the 350,000 computers added to the Internet between January 1991 and January 1992, or the 600,000 in the year after that, or the 1.1 million in the year after that.
Yet I will dare to venture onto this epistemically shaky ground, and assert that three overlapping waves of users account for the explosion of the Internet, each with their own reasons for joining, but all drawn by the inexorable logic of Metcalfe’s Law, which indicates that the value (and thus the attractive force) of a network increases with the square of its number of participants.
First came the academic users. The NSF had intentionally spread computing to as many universities as possible. Now every academic wanted to be on board, because that’s where the other academics were. To be unreachable by Internet email, to be unable to see and participate in the latest discussions on Usenet, was to risk missing an important conference announcement, a chance to find a mentor, cutting-edge pre-publication research, and more. Under this pressure to be part of the online academic conversation, universities quickly joined onto the regional networks that could connect them to the NSFNET backbone. NEARNET, for example, which covered the six states of the New England region, grew to over 200 members by the early 1990s.
At the same time, access began to trickle down from faculty and graduate students to the much larger undergraduate population. By 1993, roughly 70% of the freshman class at Harvard had edu email accounts. By that time the Internet also became physically ubiquitous at Harvard and its peer institutions, which went to considerable expense to wire Ethernet into not just every academic building, but even the undergrad dormitories (12). It was surely not long before the first student stumbled into his or her room after a night of excess, slumped into their chair, and laboriously pecked out an electronic message that they would regret in the morning, whether a confession of love or a vindictive harangue.
In the next wave, the business users arrived, starting around 1990. As of that year, 1151 .com domains had been registered. The earliest commercial participants came from the research departments of high-tech companies (Bell Labs, Xerox, IBM, and so on) They, in effect, used the network in an academic capacity. Their employers’ business communications went over other networks. By 1994, however, over 60,000 .com domain names existed, and the business of making money on the Internet had begun in earnest (13).
As the 1980s waned, computers were becoming a part of everyday life at work and home in the U.S, and the importance of a digital presence to any substantial business became obvious. Email offered easy and extremely fast communication with co-workers, clients, and vendors. Mailing lists and Usenet provided both new ways of keeping up to date with a professional community, and new forms of very cheap advertising to a generally affluent set of users. A wide variety of free databases could be accessed via the Internet – legal, medical, financial, and political. New graduates arriving into the workforce from fully-wired campuses also became proselytes for the Internet at their employers. It offered access to a much larger set of users than any single commercial service (Metcalfe’s Law again), and once you paid a monthly fee for access to the net, almost everything else was free, unlike the marginal hourly and per-message fees charged by CompuServe and its equivalents. Early entrants to the Internet marketplace included mail-order software companies like The Corner Store of Litchfield, Connecticut, which advertised in Usenet discussion groups, and The Online Bookstore, an electronic books seller founded over a decade before the Kindle by a former editor at Little, Brown (14).
Finally came the third wave of growth, the arrival of ordinary consumers, who began to access the Internet in large numbers in the mid-1990s. By this point Metcalfe’s Law was operating in overdrive. Increasingly, to be online meant to be on the Internet. Unable to afford T1 lines to their homes, consumers almost always accessed the Internet over a dial-up modem. We have already seen part of that story, with the gradual transformation of commercial BBSes into commercial Internet Service Providers (ISPs). This change benefited both the users (whose digital swimming pool suddenly grew into an ocean) and the BBS itself, which could run a much simpler business as an intermediary between the phone system and a T1 on-ramp to the Internet, without maintaining their own services.
Larger online services followed a similar pattern. By 1993, all of the major national-scale services in the U.S. – Prodigy, CompuServe, GEnie and upstart America Online (AOL) – offered their 3.5 million combined subscribers the ability to send email to Internet addresses. Only laggard Delphi (with less than 100,000 subscribers), however, offered full Internet access (15). Over the next few years, though, the value of access to the Internet – which continued to grow exponentially – rapidly outstripped that of accessing the services’ native forums, games, shopping and other content. 1996 was the tipping point – by October of that year, 73% of those online reported having used the World Wide Web, compared to just 21% a year earlier (16). The new term “portal” was coined, to describe the vestigial residue of content provided by AOL, Prodigy, and others, to which people subscribed mainly to get access to the Internet.
The Secret Sauce
We have seen, then, something of how the Internet grew so explosively, but not quite enough to explain why. Why, in particular, did it become so dominant in the face of so much prior art, so many other services that were striving for growth during the era of fragmentation that preceded it?
Government subsidy helped, of course. The funding of the backbone aside, when NSF chose to invest seriously in networking as an independent concern from its supercomputing program, it went all in. The principal leaders of the NSFNET program, Steve Wolff and Jane Caviness, decided that they were building not just a supercomputer network, but a new information infrastructure for American colleges and universities. To this end, they set up the Connections program, which offset part of the cost for universities to get onto the regional nets, on the condition that they provide widespread access to the network on their campus. This accelerated the spread of the Internet both directly and indirectly. Indirectly, since many of those regional nets then spun-off for-profit enterprises using this same subsidized infrastructure to sell Internet access to businesses.
But Minitel had subsidies, too. The most distinct characteristic of the Internet, however, was it layered, decentralized architecture, and attendant flexibility. IP allowed networks of a totally different physical character to share the same addressing system, and TCP ensured that packets were delivered to their destination. And that was all. Keeping the core operations of the network simple allowed virtually any application to be built atop it. Most importantly, any user could contribute new functionality, as long as they could get others to run their software. For example, file transfer (FTP) was among the most common uses of the early Internet, but it was very hard to find servers that offered files of interest for download except by word-of-mouth. So enterprising users built a variety of protocols to catalog and index the net’s FTP servers, such as Gopher, Archie, and Veronica.
The OSI stack also had this flexibility, in theory, and the official imprimatur of international organizations and telecommunications giants as the anointed internetworking standard. But possession is nine-tenths of the law, and TCP/IP held the field, with the decisive advantage of running code on thousands, and then millions, of machines.
The devolution of control over the application layer to the edges of the network had another important implication. It meant that large organizations, used to controlling their own bailiwick, could be comfortable there. Businesses could set up their own mail servers and send and receive email without all the content of those emails sitting on someone else’s computer. They could establish their own domain names, and set up their own websites, accessible to everyone on the net, but still entirely within their own control.
The World Wide Web – ah – that was the most striking example, of course, of the effects of layering and decentralized control. For two decades, systems from the time-sharing systems of the 1960s through to the likes of CompuServe and Minitel had revolved around a handful of core communications services – email, forums, and real-time chat. But the Web was something new under the sun. The early years of the web, when it consisted entirely of bespoke, handcrafted pages, were nothing like its current incarnation. Yet bouncing around from link to link was already strangely addictive – and it provided a phenomenally cheap advertising and customer support medium for businesses. None of the architects of the Internet had planned for the Web. It was the brainchild of Tim Berners-Lee, a British engineer at the European Organization for Nuclear Research (CERN), who created it in 1990 to help disseminate information among the researchers at the lab. Yet could easily rest atop TCP/IP, and re-use the domain-name system, created for other purposes, for its now-ubiquitous URLs. Anyone with access to the Internet could put up a site, and by the mid-1990s it seemed everyone had – city governments, local newspapers, small businesses, and hobbyists of every stripe.
Privatization
In this telling of the story of the Internet’s growth, I have elided some important events, and perhaps left you with some pressing questions. Notably, how did businesses and consumers get access to an Internet centered on NSFNET in the first place – to a network funded by the U.S. government, and ostensibly intended to serve the academic research community? To answer this, the next installment will revisit some important events which I have quietly passed over, events which gradually but inexorably transformed a public, academic Internet into a private, commercial one.
Further Reading
Janet Abatte, Inventing the Internet (1999)
Karen D. Fraser “NSFNET: A Partnership for High-Speed Networking, Final Report” (1996)
John S. Quarterman, The Matrix (1990)
Peter H. Salus, Casting the Net (1995)
Footnotes
Note: The latest version of the WordPress editor appears to have broken markdown-based footnotes, so these are manually added, without links. My apologies for the inconvenience.
- Abbate, Inventing the Internet, 143.
- The next time DARPA would initiate a pivotal computing project was with the Grand Challenges for autonomous vehicles of 2004-2005. The most famous project in-between, the billion-dollar AI-based Strategic Computing Initiative of the 1980s, produced a few useful applications for the military, but no core advances applicable to the civilian world.
- “1980 National Science Foundation Authorization, Hearings Before the Subcommittee on Science, Researce [sic] and Technology of the Committee on Science and Technology”, 1979.
- Smarr, “The Supercomputer Famine in American Universities” (1982)
- A snapshot of what this first iteration of NSFNET was like can be found in David L. Mills, “The NSFNET Backbone Network” (1987)
- The T1 connection standard, established by AT&T in the 1960s, was designed to carry twenty-four telephone calls, each digitally encoded at 64 kilobits-per-second.
- MERIT originally stood for Michigan Educational Research Information Triad. The state of Michigan pitched in $5 million of its own to help its homegrown T1 network get off the ground.
- Of course, the name and concept of Internet predates the NSFNET. The Internet Protocol dates to 1974, and there were networks connected by IP prior to NSFNET. ARPANET and MILNET we have already mentioned. But I have not been able to find any reference to “the Internet” – a single, all-encompassing world-spanning network of networks – prior to the advent of the three-tiered NSFNET.
- See this data. Given this trend, how could Quarterman fail to see that the Internet was destined to dominate the world? If the recent epidemic has taught is anything, it is that exponential growth is extremely hard for the human mind to grasp, as it accords with nothing in our ordinary experience.
- These figures come from Karen D. Fraser “NSFNET: A Partnership for High-Speed Networking, Final Report” (1996).
- See Salus, Casting the Net, 220-221.
- Mai-Linh Ton, “Harvard, Connected: The Houses Got Internet,” The Harvard Crimson, May 22, 2017.
- IAPS, “The Internet in 1990: Domain Registration, E-mail and Networks;” RFC 1462, “What is the Internet;” Resnick and Taylor, The Internet Business Guide, 220.
- Resnick and Taylor, The Internet Business Guide, xxxi-xxxiv. Pages 300-302 lay out the pros and cons of the Internet and commercial online services for small businesses.
- Statistics from Rosalind Resnick, Exploring the World of Online Services (1993).
- Pew Research Center, “Online Use,” December 16, 1996.

[…] [Previous] [Next] […]
LikeLike
Great write up as always. Having lived through this period (got on the Internet as a freshman circa 1987-1988), in my experience the net a definite and dramatic chance with the arrival of the killer app, the Web. Email is often cited as the killer app and it was why most people wanted it (that and Usenet), but with the Web they NEEDED it. It didn’t take business long to catch on.
I posit that the general population doesn’t really understand that the Web and Internet are not the same thing.
LikeLike
[…] [Previous] [Next] […]
LikeLike
Wonderful article! Very refreshing to read about the technical history!
LikeLike
Great readinng
LikeLike